快速入门
开始创建后写管道
本指南将引导您完成 write-behind 管道的创建。
概念
Write-behind 是一种处理管道,用于将 Redis 数据库中的数据与下游数据存储同步。 您可以将其视为一个管道,从 Redis 数据库的变更数据捕获 (CDC) 事件开始,然后筛选、转换数据并将其映射到目标数据存储数据结构。
write-behind 管道连接并写入数据的目标数据存储。
write-behind 管道由一个或多个作业组成。每个作业负责捕获 Redis 中一个键模式的更改,并将其映射到下游数据存储中的一个或多个表。每个作业都在 YAML 文件中定义。
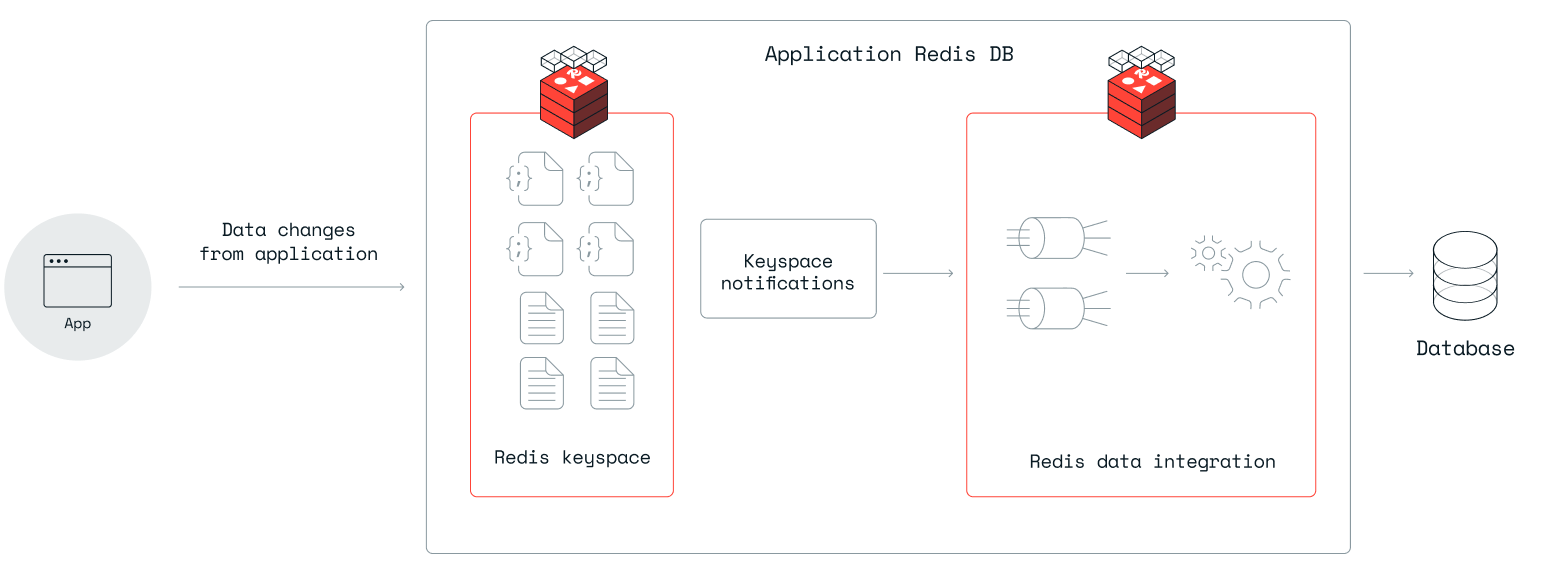
支持的数据存储
Write-behind 目前支持以下目标数据存储:
| 数据存储 |
|---|
| 卡珊德拉 |
| MariaDB的 |
| MySQL (MySQL的 |
| 神谕 |
| PostgreSQL 数据库 |
| Redis 企业版 |
| SQL 服务器 |
先决条件
运行后写的唯一先决条件是 Redis Gears Python >= 1.2.6,安装在 Redis Enterprise Cluster 上,并为要镜像到下游数据存储的数据库启用。 有关更多信息,请参阅 RedisGears 安装。
准备 write-behind 管道
-
在连接到 Redis Enterprise Cluster 的 Linux 主机上安装 Write-behind CLI。
-
运行
configure命令在您的 Redis 数据库上安装 Write-behind 引擎(如果您之前没有将此 Redis 数据库与 Write-behind 一起使用)。 -
运行
scaffold命令替换为要使用的数据存储类型,例如:redis-di scaffold --strategy write_behind --dir . --db-type mysqlThis creates a templateconfig.yamlfile and a folder namedjobsunder the current directory. You can specify any folder name with--diror use the--preview config.yamloption, if your Write-behind CLI is deployed inside a Kubernetes (K8s) pod, to get theconfig.yamltemplate to the terminal. -
Add the connections required for downstream targets in the
connectionssection ofconfig.yaml, for example:connections: my-postgres: type: postgresql host: 172.17.0.3 port: 5432 database: postgres user: postgres password: postgres #query_args: # sslmode: verify-ca # sslrootcert: /opt/work/ssl/ca.crt # sslkey: /opt/work/ssl/client.key # sslcert: /opt/work/ssl/client.crt my-mysql: type: mysql host: 172.17.0.4 port: 3306 database: test user: test password: test #connect_args: # ssl_ca: /opt/ssl/ca.crt # ssl_cert: /opt/ssl/client.crt # ssl_key: /opt/ssl/client.keyThis is the first section of theconfig.yamlfile and typically the only one you'll need to edit. Theconnectionssection is designed to have many target connections. In the previous example, there are two downstream connections namedmy-postgresandmy-mysql.To obtain a secured connection using TLS, you can add more
connect_argsorquery_args, depending on the specific target database terminology, to the connection definition.The name can be any arbitrary name as long as it is:
- Unique for this Write-behind engine
- Referenced correctly by the jobs in the respective YAML files
In order to prepare the pipeline, fill in the correct information for the target data store. Secrets can be provided using a reference to a secret (see below) or by specifying a path.
The applier section has information about the batch size and frequency used to write data to the target.
Some of the applier attributes such as target_data_type, wait_enabled, and retry_on_replica_failure are specific for the Write-behind ingest pipeline and can be ignored.
Write-behind jobs
Write-behind jobs are a mandatory part of the write-behind pipeline configuration.
Under the jobs directory (parallel to config.yaml) you should have a job definition in a YAML file for every key pattern you want to write to a downstream database table.
The YAML file can be named using the destination table name or another naming convention, but it has to have a unique name.
Job definition has the following structure:
source:
redis:
key_pattern: emp:*
trigger: write-behind
exclude_commands: ["json.del"]
transform:
- uses: rename_field
with:
from_field: after.country
to_field: after.my_country
output:
- uses: relational.write
with:
connection: my-connection
schema: my-schema
table: my-table
keys:
- first_name
- last_name
mapping:
- first_name
- last_name
- address
- gender
Source section
The source section describes the source of data in the pipeline.
The redis section is common for every pipeline initiated by an event in Redis, such as applying changes to data. In the case of write-behind, it has the information required to activate a pipeline dealing with changes to data. It includes the following attributes:
-
The key_pattern attribute specifies the pattern of Redis keys to listen on. The pattern must correspond to keys that are of Hash or JSON type.
-
The exclude_commands attribute specifies which commands to ignore. For example, if you listen on a key pattern with Hash values, you can exclude the HDEL command so no data deletions will propagate to the downstream database. If you don't specify this attribute, Write-behind acts on all relevant commands.
-
The trigger attribute is mandatory and must be set to write-behind.
-
The row_format attribute can be used with the value full to receive both the before and after sections of the payload. Note that for write-behind events the before value of the key is never provided.
Note: Write-behind does not support the expired event. Therefore, keys that are expired in Redis will not be deleted from the target database automatically.
Notes: The redis attribute is a breaking change replacing the keyspace attribute. The key_pattern attribute replaces the pattern attribute. The exclude_commands attributes replaces the exclude-commands attribute. If you upgrade to version 0.105 and beyond, you must edit your existing jobs and redeploy them.
Output section
The output section is critical. It specifies a reference to a connection from the config.yaml connections section:
-
The uses attribute specifies the type of writer Write-behind will use to prepare and write the data to the target.
In this example, it is relational.write, a writer that translates the data into a SQL statement with the specific dialect of the downstream relational database.
For a full list of supported writers, see
data transformation block types.
-
The schema attribute specifies the schema/database to use (different database have different names for schema in the object hierarchy).
-
The table attribute specifies the downstream table to use.
-
The keys section specifies the field(s) in the table that are the unique constraints in that table.
-
The mapping section is used to map database columns to Redis fields with different names or to expressions. The mapping can be all Redis data fields or a subset of them.
Note: The columns used in keys will be automatically included, so there's no need to repeat them in the mapping section.
Apply filters and transformations to write-behind
The Write-behind jobs can apply filters and transformations to the data before it is written to the target. Specify the filters and transformations under the transform section.
Filters
Use filters to skip some of the data and not apply it to target.
Filters can apply simple or complex expressions that take as arguments the Redis entry key, fields, and even the change op code (create, delete, update, etc.).
See Filter for more information.
Transformations
Transformations manipulate the data in one of the following ways:
- Renaming a field
- Adding a field
- Removing a field
- Mapping source fields to use in output
To learn more about transformations, see
data transformation pipeline.
Provide target's secrets
The target's secrets (such as TLS certificates) can be read from a path on the Redis node's file system. This allows the consumption of secrets injected from secret stores.
Deploy the write-behind pipeline
To start the pipeline, run the
deploy command:
redis-di deploy
You can check that the pipeline is running, receiving, and writing data using the
status command:
redis-di status
Monitor the write-behind pipeline
The Write-behind pipeline collects the following metrics:
Metric Description
Metric in Prometheus
Total incoming events by stream
Calculated as a Prometheus DB query: sum(pending, rejected, filtered, inserted, updated, deleted)
Created incoming events by stream
rdi_metrics_incoming_entries{data_source:"…",operation="inserted"}
Updated incoming events by stream
rdi_metrics_incoming_entries{data_source:"…",operation="updated"}
Deleted incoming events by stream
rdi_metrics_incoming_entries{data_source:"…",operation="deleted"}
Filtered incoming events by stream
rdi_metrics_incoming_entries{data_source:"…",operation="filtered"}
Malformed incoming events by stream
rdi_metrics_incoming_entries{data_source:"…",operation="rejected"}
Total events per stream (snapshot)
rdi_metrics_stream_size{data_source:""}
Time in stream (snapshot)
rdi_metrics_stream_last_latency_ms{data_source:"…"}
To use the metrics you can either:
-
Run the status command:
redis-di status
-
Scrape the metrics using Write-behind's Prometheus exporter
Upgrading
If you need to upgrade Write-behind, you should use the
upgrade command that provides for a zero downtime upgrade:
redis-di upgrade ...
On this page